笔者作为AWS官方认证的早期通过者,已经拿到了AWS的助理级解决方案架构师、开发者认证,系统管理员认证。这几年也陆续指导公司多人通过AWS的认证。本篇文章将分享如何通过自学的方式轻松通过AWS的助理级架构师、开发者和系统管理员认证。
为什么要考证
在讲述AWS的认证体系之前,我们可以先探讨一下为什么要考取这样的认证。根据我接触的考证的人,总结出考证的原因主要是以下几个方面:
通过考证提高自己的竞争力。这是大部分想考证的人的目的。https://blog.cbtnuggets.com/2016/07/10-high-paying-it-certifications/一文中列出了IT领域薪资最高的10个证书,第一名就是AWS解决方案架构师认证。拿到认证的人员的平均年薪为125,871美元。在云计算领域,AWS是当之无愧的NO.1。阿里云在早期就是对标AWS,很多服务都是参照AWS做的。不过阿里云在国内市场的环境下也有创新,比如其开发的云盾产品,在各大云计算厂商中走到了前面。AWS随后也推出了类似的产品。
公司或部门要求员工考证。现在越来越的传统组织和企业拥抱公有云。据资料统计,目前有将近60%的国内网站运行在阿里云上。在拥抱云计算的同时,这些企业内的IT组织人员就需要掌握云计算相关的知识和技能。而考取认证可能就会成为企业和部门对公司部分员工的要求。另外云计算是一个很大的市场,除了各大云计算厂商外,他们都有很多合作伙伴。AWS也不例外。而要成为AWS的合作伙伴,则对公司内部考取认证的人数有一定要求。这也促使这些合作伙伴要求员工考证。
通过考证检验自己的技能学习情况。笔者就属于这个原因。笔者自从2012年接触AWS,至今已经将近5年。笔者在2013年通过了AWS的助理级解决方案架构师认证。后来也通过了开发者认证。目前正在积极备战解决方案架构师认证。
其实无论考证是处于什么目的,我想说应该抱着掌握AWS服务的使用的目的来学习AWS,考证只是对自己掌握情况的检验。有个考取了专家级解决方案架构师认证的同事打过这样一个比喻,AWS认证就像是一名登山者所带的一盒午餐,当他爬到山顶后,可以享用这盒午餐。而他收获的肯定不仅仅是这盒午餐,而是沿途上的风景,午餐只是附赠品。如果单纯为了花费最小的力气来通过认证,往往会事倍功半。
AWS的认证体系
AWS的认证有路线图,主要分为Architecting(架构)、Developing(开发)、Operations(运维)三条线。每条线又分为助理级认证和专家级认证,必须通过助理级认证后才能考取相应的专家级认证。架构这条线的两个认证为助理级解决方案架构师认证和专家级解决方案架构师认证。开发这条线的两个认证为开发者认证和DevOps工程师认证。运维这条线的两个认证为SysOps系统管理员认证和DevOps工程师认证。也就是说开发和运维两条线的专家级认证是同一个证书。
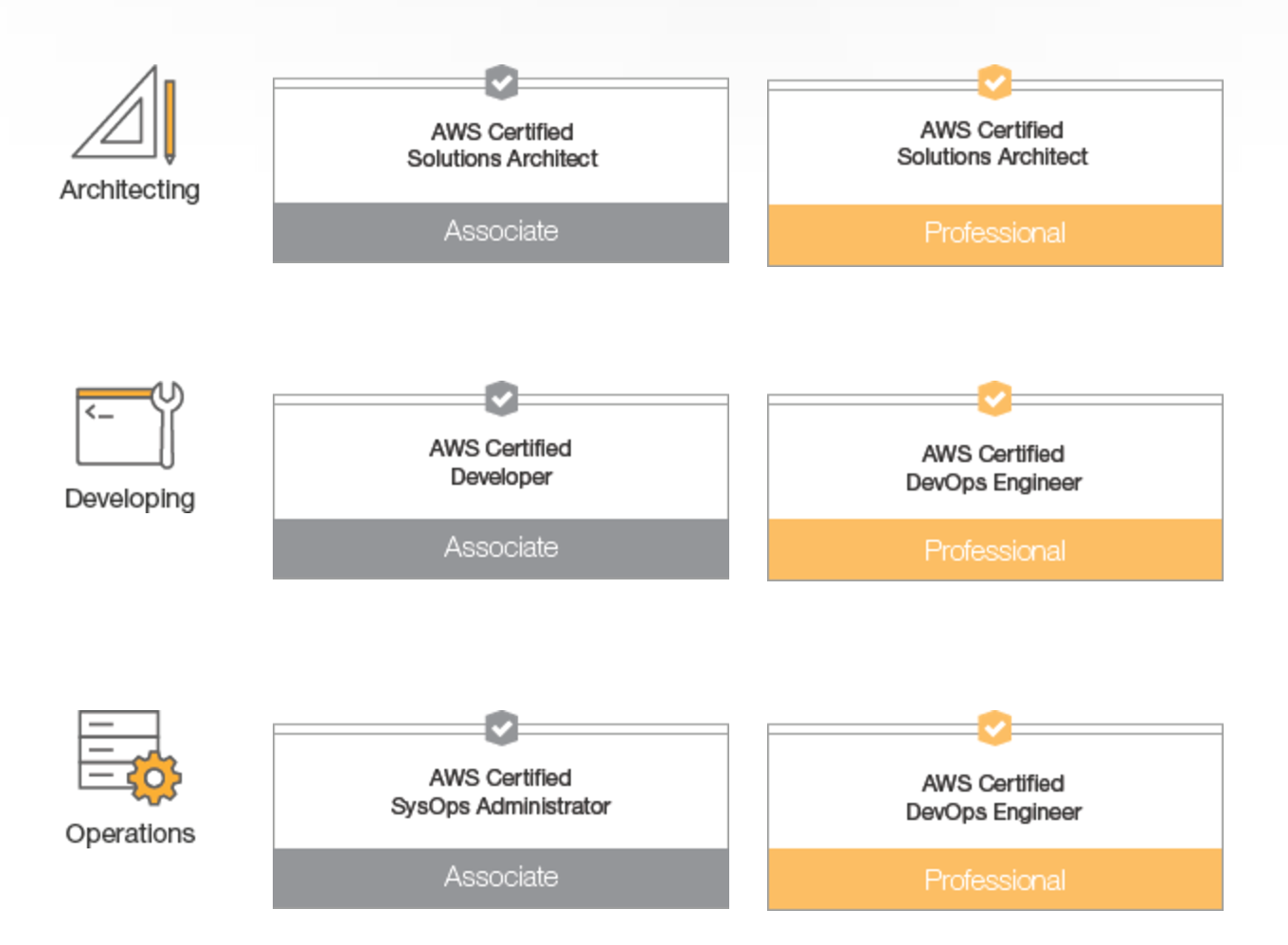
举个例子,如果想考取专家级解决方案架构师认证,那必须先考取助理级解决方案架构师认证才行。而要考取DevOps工程师认证,则先要考取开发者认证或SysOps系统管理员认证两个证中其中最少一个。
另外每个证书都有有效期,其有效期为两年。到期之后可以重新认证。重新认证的费用和题量减半。由于云计算现在还处于高速发展的阶段,AWS每年都会推出很多新的云服务,也会对现有的服务升级。为了避免你掌握的知识过时,设置证书两年过期还是比较合理的。
本书主要讲述三个助理级认证的考经,由于专家级认证考试范围、考试难度、备考方式完全不一样,所以本文不会过多涉及。
选择适合自己的证书
根据笔者的了解,助理级认证中考取解决方案架构师的居多,而开发者和SysOps的人比较少。可能是因为每个IT技术人员都有一个当架构师的梦吧。其实笔者从考试经验来说,无论你选择哪种助理级证书,在备考的时候其实都是差不多的。也就是说用一种备考方式,可以三证通吃。根据笔者的经验,这三个证书考取的难易程度如下:开发者认证<助理级解决方案架构师认证<SysOps系统管理员认证。也就是说开发者认证难度最小,SysOps系统管理员认证稍难些,助理级解决方案架构师认证居中。
每个认证都有一个考试指南,目前只有英文版。上面有对想考取认证的人员的AWS知识和IT知识有要求。大家可以根据这些要求来判断自己考取哪个证书更有把握。
AWS助理级解决方案架构师的考试指南地址为:http://awstrainingandcertification.s3.amazonaws.com/production/AWS_certified_solutions_architect_associate_blueprint.pdf。
AWS开发者认证的考试指南地址为:http://awstrainingandcertification.s3.amazonaws.com/production/AWS_certified_developer_associate_blueprint.pdf。
AWS SysOps系统管理员认证的考试指南地址为:http://awstrainingandcertification.s3.amazonaws.com/production/AWS_certified_sysops_associate_blueprint.pdf。
我们以开发者认证的要求为例,看看想考取该证书需要具备什么样的能力。
AWS知识:
- 使用AWS技术的专业经验
- 使用AWS API的实战经验
- 了解AWS安全最佳实践
- 了解自动化和AWS部署工具
- 了解存储选项和其低层的一致性模型
- 非常了解至少一种AWS SDK
通用IT知识:
- 了解无状态和松散耦合的分布式应用程序
- 熟悉RESTful API接口开发
- 对关系型和非关系型数据的理解
- 熟悉消息和队列服务
如果你目前还未达到指定的要求,没关系。至少知道了自己的薄弱点,通过学习补强再考。
证书题型和考试相关
目前助理级证书都提供英文和中文试卷。这对于英文不好的同学是一个福音。(想当年笔者考试的时候只有英文试卷)。助理级考试有模拟考试和正式考试。模拟考试为费用为20美元,共有20道题目,考试时间为30分钟。注意模拟考试最多考一次就行了。因为第二次的题目会和第一次的题目一模一样。正式考试费用为150美元,也可以通过中国认证合作伙伴通过人民币购买,费用为1,150人民币。正式考试有55道题,考试时间为80分钟。
AWS的认证题目都是选择题,有单选题和多选题。多选题题目会明确的告诉你有几个正确选项。每个助理级认证都有相应的样题,供你熟悉考试题型。
AWS 助理级解决方案架构师认证的样题及解析可参见我的博客:http://www.huangbowen.net/blog/2014/10/22/aws-cert-sample-question/。
AWS 开发者认证的样题及解析可参见我的博客:http://www.huangbowen.net/blog/2016/07/27/aws-developer-exam-sample-questions/。
AWS SysOps系统管理员认证的样题及解析可参见我的博客:http://www.huangbowen.net/blog/2016/08/01/aws-sysops-exam-sample/。
我们可以助理级解决方案架构师认证的几个题目作为示例。
Amazon Glacier is designed for: (Choose 2 answers)
A.active database storage.
B.infrequently accessed data.
C.data archives.
D.frequently accessed data.
E.cached session data.
这是一个典型的多选题。题目明确告诉有两个正确选项。正确答案为B何C。因为AWS官方文档是这样描述Glacier的:
Amazon Glacier is an extremely low-cost cloud archive storage service that provides secure and durable storage for data archiving and online backup. In order to keep costs low, Amazon Glacier is optimized for data that is infrequently accessed and for which retrieval times of several hours are suitable.
段落出处为:http://aws.amazon.com/glacier/?nc2=h_ls
Your web application front end consists of multiple EC2 instances behind an Elastic Load Balancer. You configured ELB to perform health checks on these EC2 instances. If an instance fails to pass health checks, which statement will be true?
A.The instance is replaced automatically by the ELB.
B.The instance gets terminated automatically by the ELB.
C.The ELB stops sending traffic to the instance that failed its health check.
D.The instance gets quarantined by the ELB for root cause analysis.
这是一个单选题,正确答案为C。因为AWS官方文档有这样一项描述:
Elastic Load Balancing ensures that only healthy Amazon EC2 instances receive traffic by detecting unhealthy instances and rerouting traffic across the remaining healthy instances.
本段落的出处为:http://aws.amazon.com/elasticloadbalancing/?nc2=h_ls。
考试并没有详细的分数线。AWS 认证的分数线是依据统计分析结果来设定的,并不固定。AWS 不会公布考试的分数线,因为试题和分数线可能会更改而不另行通知。2013年的时候,根据经验一般正确率达到65%以上就可以通过考试,拿到认证。但近年来这个比例也在上升。目前至少要70%以上才有保险拿到证书。
认证准备篇
其实没有必要被认证的考试指南中的要求吓到。有些技能我们可能目前不具备,但可以通过学习来掌握。
AWS目前有近百项服务,分为18个类别。要想全部掌握要花的时间可不少。不过如果想通过AWS的助理级认证,只需要熟悉掌握主要的服务即可。对其他服务只需要明白其使用场景以及一些应用限制。
我认为需要熟练掌握的服务:
- Amazon EC2
- Amazon VPC
- Amazon S3
- Amazon EBS
- Amazon RDS
- Amazon DynamoDB
- Elastic Load Balancing
- Amazon CloudWatch
- AWS Identity & Access Management
- Amazon Simple Queue Service
知道其应用场景和限制条件的服务有:
- Amazon Glacier
- Amazon ElastiCache
- Amazon Redshift
- Amazon CloudFront
- Amazon Route53
- AWS CloudFormation
- AWS Config
- AWS CloudTrial
- AWS WAF
- Amazon Simple Notification Service
- Amazon Simple Email Service
- AWS Import/Export
- AWS connect
对于需要熟练掌握的服务,每个必须都要进行实战演练。而第二类服务,如果不想花费太多时间,可以不必进行实战演练,查看相关的文档即可。
在开始学习之前,请先去aws.amazon.com的官网注册一个新的账号。因为AWS对于新的账号有free tier(免费套餐)服务。AWS 免费套餐服务/产品包括自 AWS 注册之日起 12 个月内可供免费使用的服务,以及在 AWS 免费套餐的 12 个月期限到期后不自动过期的其他服务/产品。我上面列出的所有服务基本上都在AWS免费套餐范围内。拿Amazon EC2来说,在新账号注册后的12月内,你可以享受750 小时 每月 Linux、RHEL 或 SLES t2.micro 实例使用时间,以及750 小时 每月 Windows t2.micro 实例使用时间。 例如,运行 1 个实例 1 个月,或运行 2 个实例半个月都是免费的。这样的免费套餐足够我们进行实战演练了。注意账号时需要绑定一张自己的信用卡,否则无法注册成功。
注意目前AWS分为中国区和全球区,中国区和全球区的账号是不能通用的。并且中国区账号并没有免费套餐服务,所以只有注册全球区的账号才可以使用免费套餐服务。
认识并熟悉专业术语
在学习AWS初期,你一定会听到各种各样的缩写词,很容易迷失。这些专业术语有的是和AWS服务紧密相关的,比如ELB(Elastic Load Balancing服务的缩写)、SQS(Amazon Simple Queue Service的缩写)等。有些是跟网络安全紧密相关的,比如ACL、AAD、SG、MFA等;有跟应用程序服务相关的,比如SOAP、WSDL、WAF等。每当你看到一个不懂的术语时,先记下来,然后弄清楚它的意思。这样随着时间的推移不懂的术语会越来越少。你可以查看AWS官方的术语表来进行巩固。英文版本为http://docs.aws.amazon.com/general/latest/gr/glos-chap.html。中文版本为http://docs.aws.amazon.com/zh_cn/general/latest/gr/glos-chap.html。
学会查看AWS官方文档
要学习AWS,最好的文档当然是AWS的官方文档。目前AWS的官方文档有80%都进行了汉化处理。也就是说如果英文不是很好的同学可以看中文的文档。
访问https://aws.amazon.com/cn/products/?nc2=h_ql_ny_gsc可以看到AWS提供的所有服务,最上面的菜单可以切换语言。我们以想要了解EC2为例,点击计算类别,可以看到Amazon EC2。点击该服务后就会进入Amazon EC2的主页https://aws.amazon.com/cn/ec2/?p=tile。这里列出了EC2的介绍以及其优势。这些内容务必仔细学习,能够让你迅速了解一门产品并且明白其使用场景和优势。
点击菜单栏的产品详细信息可以进入到另一个页面:https://aws.amazon.com/cn/ec2/details/。这里不仅有产品详情,还有开发人员资源、常见问题以及入门手册。如果想动手练习对EC2的使用,可以访问https://aws.amazon.com/cn/documentation/ec2/。里面提供了HTML/PDF/Kindle三种格式的入门指南。可以按照入门指南的操作步骤进行操作学习。
每个服务都有常见问题页,比如EC2的常见问题页是https://aws.amazon.com/cn/ec2/faqs/。每个服务的常见问题页都必须要熟读并掌握,因为至少70%的考题的答案都可以在常见问题中找到。但是单纯背诵这些内容是无意义的,很容易忘记。必须要明白AWS每个问题的答案的背后意义,这样才有助于记忆。
查看AWS的白皮书
AWS官方文档对每个服务介绍的非常详细,但内容很多,看起来比较累。而AWS的白皮书则总结了使用AWS的一些最佳实践和方式,并针对一些具体场景结合相应服务的特点给出了最适合的架构设计。https://aws.amazon.com/cn/whitepapers/列出了AWS的所有白皮书。重点需要掌握的白皮书有:
视频和辅助网站
除了实战操作、查看文档外,观看视频也是学习的途径之一。Youtube有很多操作视频可以观看。另外cloudguru和LinuxAcademy网站上也有大量的视频教程。Cloudguru和LinuxAcademy都是需要付费的。LinuxAcademy按月付费为29美元每月,年度费用为228美元。Cloudgruru则按课程收费,比如助理级架构师认证课程费用为29美元。另外还提供打包服务,全部AWS课程的打包服务为149美元,共7门课。我备战AWS考试的时候都用过这两个网站的服务。总体感觉Linux
Academy的课程要丰富一些,并且便宜。这两个网站都提供一站式的服务。在这里你既可以观看视频学习,也可以通过其创建的AWS资源进行免费操练,更可以疯狂刷模拟题。注意这两个网站中的模拟题比正式考题的题目要简单些。模拟题的题库也不大,比如助理级架构师的题库有300多道题。我当时是刷穿了,基本上300道题做完只会错3、4道。
备考计划篇
一个没有什么AWS使用经验的IT工作人员,想要考取AWS助理级认证还是要花些时间的。但时间也不是想象中的那么长。我第一个认证当时认真准备了1个半月。每天至少花3个小时,最后以65%的准确率惊险过关。而第二个证则只准备了1周多,只花了20多分钟就做完了55道题,准确率达90%以上,轻松过关。根据我经验判断,如果没有AWS相关的使用经验,每天投入三小时的话,最多3个月就可以去考试了。因为需要熟练掌握的服务差不多有10多个,每三天掌握一个,需要30天的时间,而需要了解的服务也有10多个,每两天掌握一个,需要22天。剩下的一个月可以阅读白皮书、动手做实验加强理解、在网站上刷题,补充薄弱点。
每学习一个服务时,要求动手与文档相结合。尤其是必须要理解AWS管理控制台上操作时每个选项的具体含义。一般官方文档都会给出其具体意义。另外文档也会包含有实战中了解不到的内容。比如个人账户最多只能开启20个EC2,再多就需要申请;SQS消息队列中消息默认的存活时间是14天;S3中存储的最小对象可以为0KB等。这些都有可能会成为考试内容。
个人建议每学习一个服务都要动手记下笔记。俗话说眼过千遍不如手过一遍。这样也可以避免学习了后面的忘记的前面的。笔记可以时不时拿出来复习一下。
考试篇
访问https://www.aws.training/certification?src=cert-prep可以安排一场模拟考试或者正式考试。模拟考试在网上可以直接进行。正式考试则需要去相应的考点。目前在中国有成都、重庆、北京、上海、广州、杭州、长沙、大连、济南、南京、青岛、深圳、苏州、武汉、西安、厦门、郑州等城市设有考点。周一和周五都可以考试,一般提前一周报名注册即可。
正式考试时需要带上个人有效证件(比如身份证、护照、户口本)等。考试一本是一个单独的房间,只有你一个人,使用的电脑是考试方提供的电脑。我的几次考试都是在成都考的。成都这边的网络比较差劲,答完一道题后,需要等好几秒才能进入下一题。虽然页面刷新时计时器会暂停,但是非常影响节奏。考试的时候只能带笔和草稿纸,不能带任何电子设备,手机等需要放在外面。做完以后可以提前交卷,也可以等时间到以后自动交卷。交完卷后你会立马知道自己的成绩以及通过与否。
正式考试80分钟要答55道题,每道题的时间只有不到2分钟,所以时间很紧促。由于所有的题目都是选择题,那么有一个窍门是在一张A4纸上划上下面一个表格:
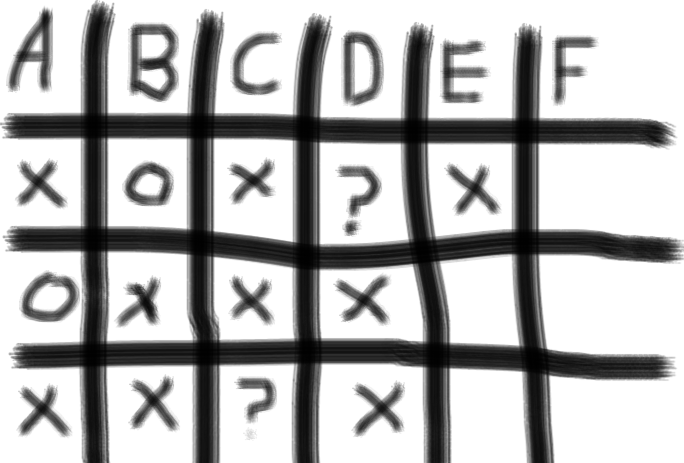
每道题为一行,对于认为绝对错误的选项划x,对于认为正确的选项划o,对于不确定的选项划?。这样有助于整理思路,然后回头检查时可以缩小范围,提高准确率。
总结
洋洋洒洒写了很多,最后再快速总结一下。
需要熟练掌握的服务(需要了解它们的方方面面):
- Amazon EC2
- Amazon VPC
- Amazon S3
- Amazon EBS
- Amazon RDS
- Amazon DynamoDB
- Elastic Load Balancing
- Amazon CloudWatch
- AWS Identity & Access Management
- Amazon Simple Queue Service
知道其应用场景和限制条件的服务有:
- Amazon Glacier
- Amazon ElastiCache
- Amazon Redshift
- Amazon CloudFront
- Amazon Route53
- AWS CloudFormation
- AWS Config
- AWS CloudTrial
- AWS WAF
- Amazon Simple Notification Service
- Amazon Simple Email Service
- AWS Import/Export
- AWS connect
备考路线图:
- 先注册AWS账号
- 阅读各个认证的考试大纲及样题
- 查看AWS常见问题页
- 根据官网文档依次学习上面的列出的服务;第一类服务需要大量的实战操作,第二类服务实战操作不是强制性,但文档需要查看;
- 查看各个服务的常见问题页
- 阅读AWS白皮书,尤其是列出的那些白皮书是必读的
- 做一遍官方模拟题
- 如果买了Cloudguru或LinuxAcademy的服务的话,可以疯狂刷网站提供的模拟考试,争取题库中的题目正确率在95%以上。
- 可以去考试了。
平心而论,AWS认证的含金量还是比较高的。因为它的考试题目(尤其是专家级的考试题目)都是综合性的,不会考什么冷僻知识点,都是现实使用中会碰到的问题。尤其是我在备战专家级解决方案架构师的认证中,了解了各种实际场景下如何结合云计算提供的服务进行架构设计。自己的架构设计能力得到了真正的提高。
]]>